# tidyverse: manipular datos, filtrar, agrupar, resumir y visualizar
library(tidyverse)
# ggplot2: crear visualizaciones con sistema de capas
library(ggplot2)Introducción a R
Documento de trabajo
1 Cargar librerías necesarias
2 Descargar y cargar datos
# Definimos la URL y el nombre del archivo
url <- "https://raw.githubusercontent.com/centrociir/interculturales/refs/heads/main/clases/clase1/bbdd/casen2022_sample.csv"
destfile <- "casen2022_sample.csv"
# Descargamos el archivo desde GitHub
download.file(url, destfile, mode = "wb")
# Cargamos el CSV descargado en un dataframe
casen <- read.csv(destfile, encoding = "UTF-8")3 Inspeccionar los primeros datos
# Mostrar primeras filas del dataset para conocer la estructura
tibble::as_tibble(head(casen))# A tibble: 6 × 11
region nse sexo ecivil educ pueblos_indigenas pobreza p9 edad yautcor
<int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 5 4 1 2 5 0 3 3 43 200000
2 4 2 1 2 5 0 3 5 27 100000
3 7 1 1 8 5 0 3 5 26 400000
4 4 1 2 8 4 0 2 5 16 NA
5 9 6 2 8 5 0 3 3 22 NA
6 5 4 2 1 2 0 3 4 43 20000
# ℹ 1 more variable: ind_hacina <int>4 Visualizaciones exploratorias
4.1 Histograma de edad
El histograma permite visualizar la distribución de la variable numérica edad dentro del conjunto de datos. Esta es una de las formas más directas de explorar cómo se distribuyen los valores de una variable continua.
Pasos del código:
casen |> ggplot(aes(edad)): inicia el gráfico utilizando la base de datos casen y mapea la variable edad al eje X.geom_histogram(color = "white"): agrega una capa de histograma (barras), usando el color blanco para el borde de las barras.
casen |> ggplot(aes(edad)) +
geom_histogram(color = "white") 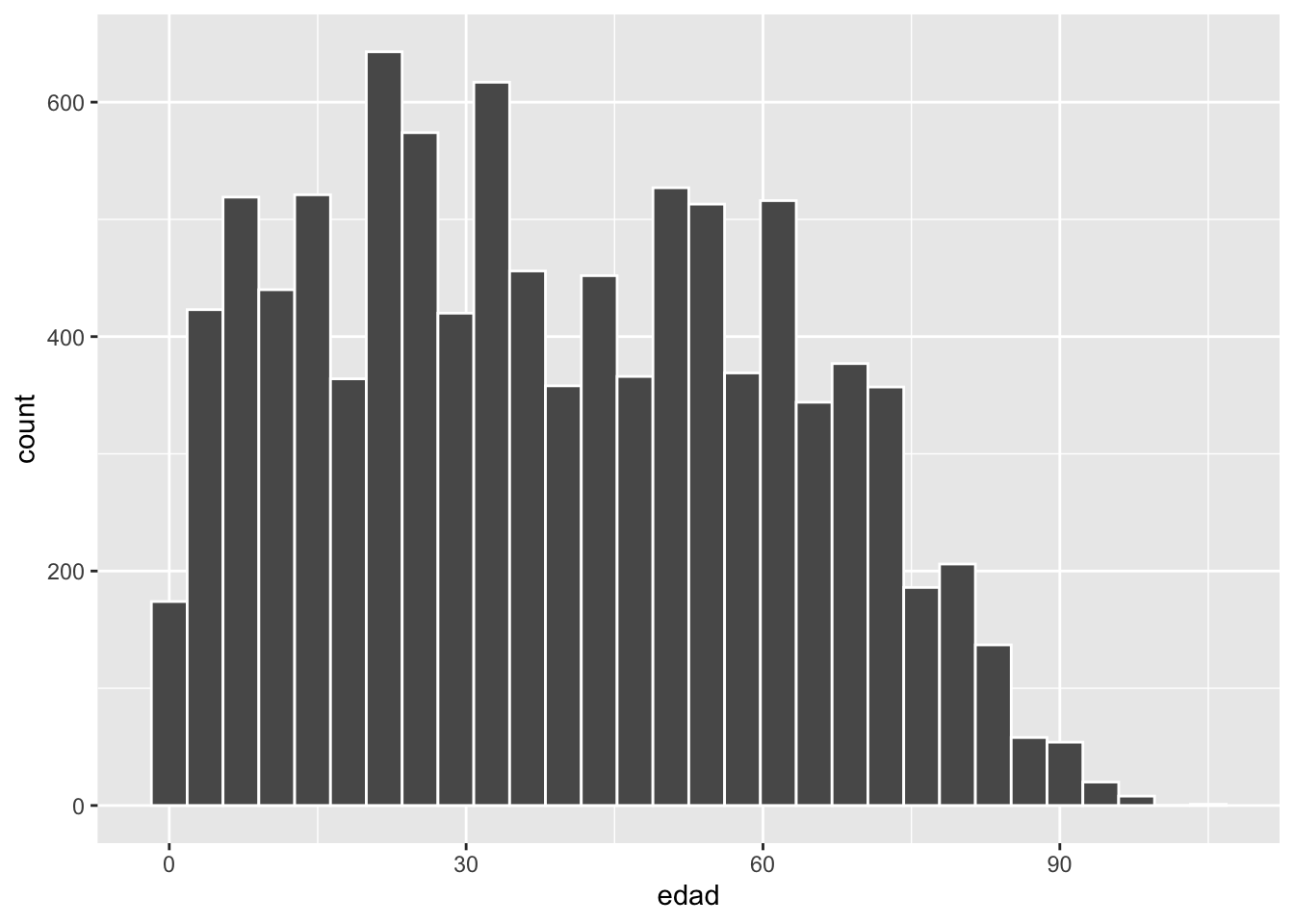
4.2 Densidad por pertenencia a pueblo indígena
Este gráfico muestra la distribución de la edad usando curvas de densidad, diferenciadas por el grupo de pertenencia indígena. A diferencia del histograma, las curvas de densidad suavizan la forma de la distribución y permiten comparar grupos más claramente.
Pasos del código:
casen |> ggplot(aes(edad, colour = pueblos_indigenas)): se define el gráfico base, mapeando la variableedadal eje X y asignando un color distinto según la variablepueblos_indigenas.geom_density(): añade la geometría de densidad, que estima la distribución de la variableedad.
casen |> ggplot(aes(edad, colour = pueblos_indigenas)) +
geom_density()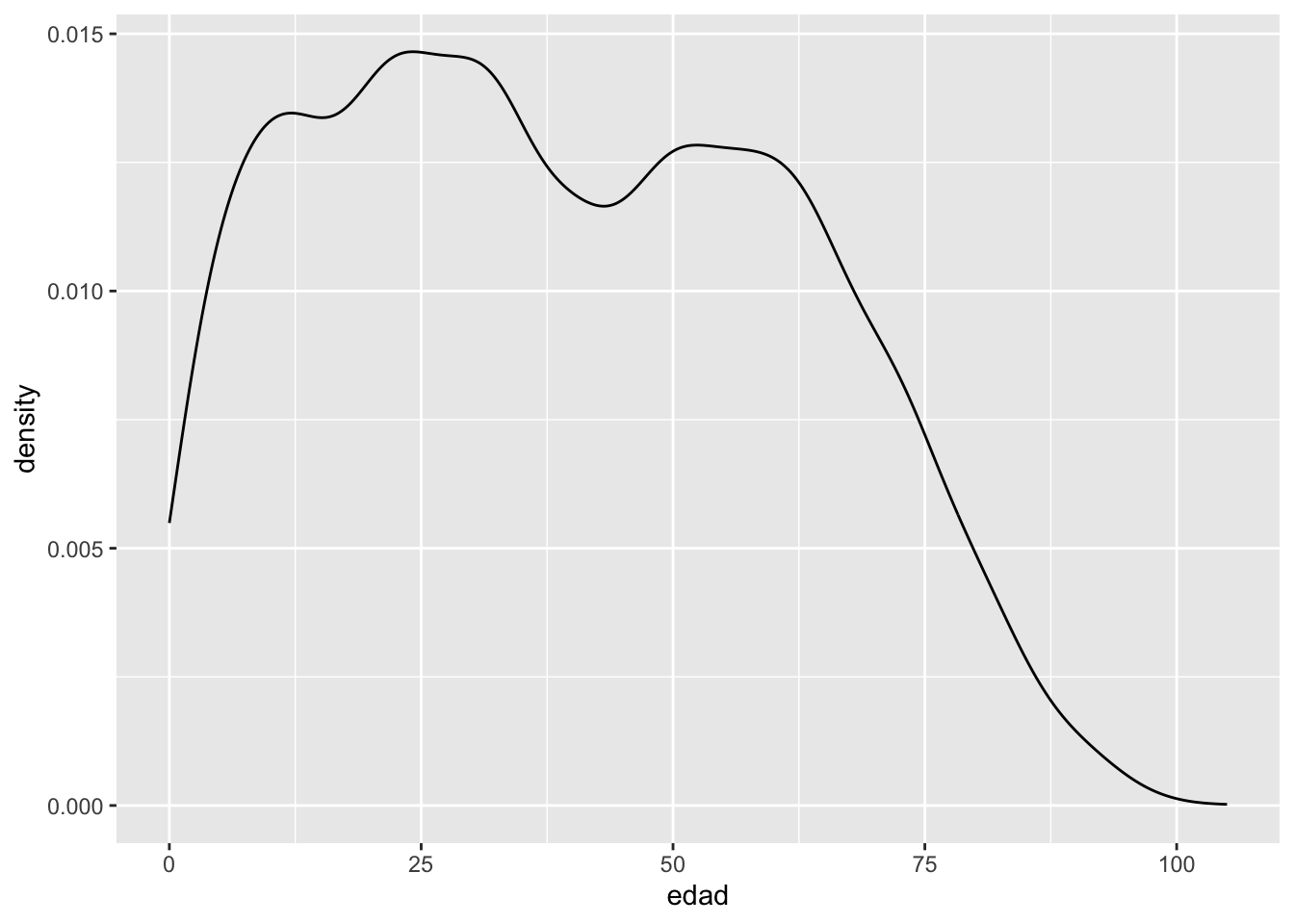
4.3 Densidad de ingresos según pueblo indígena
Este gráfico permite observar cómo se distribuye el ingreso autónomo (yautcor) en la población, distinguiendo entre personas indígenas y no indígenas. Se utiliza una curva de densidad para facilitar la comparación entre ambos grupos.
Pasos del código:
mutate(...): convierte la variablepueblos_indigenasen un factor con etiquetas legibles:"No Indígena"y"Indígena".filter(yautcor < 100000): excluye valores extremos de ingreso para evitar que distorsionen el gráfico.ggplot(...): inicia el gráfico asignando la variableyautcoral eje X, y diferenciando los grupos porfillycolor.geom_density(alpha = 0.6): genera curvas de densidad con cierta transparencia (alpha = 0.6) para que se puedan ver las superposiciones.labs(...): define título y etiquetas de los ejes.theme_classic(): aplica un tema con fondo blanco y sin cuadrículas para una presentación más limpia.
casen |>
mutate(pueblos_indigenas = factor(pueblos_indigenas, levels = c(0, 1), labels = c("No Indígena", "Indígena"))) |>
filter(yautcor < 100000) |> # eliminar extremos
ggplot(aes(x = yautcor, fill = pueblos_indigenas, color = pueblos_indigenas)) +
geom_density(alpha = 0.6) +
labs(
title = "Distribución del ingreso autónomo según pertenencia indígena",
x = "Ingreso autónomo (yautcor)",
y = "Densidad",
fill = "Pertenencia",
color = "Pertenencia"
) +
theme_classic()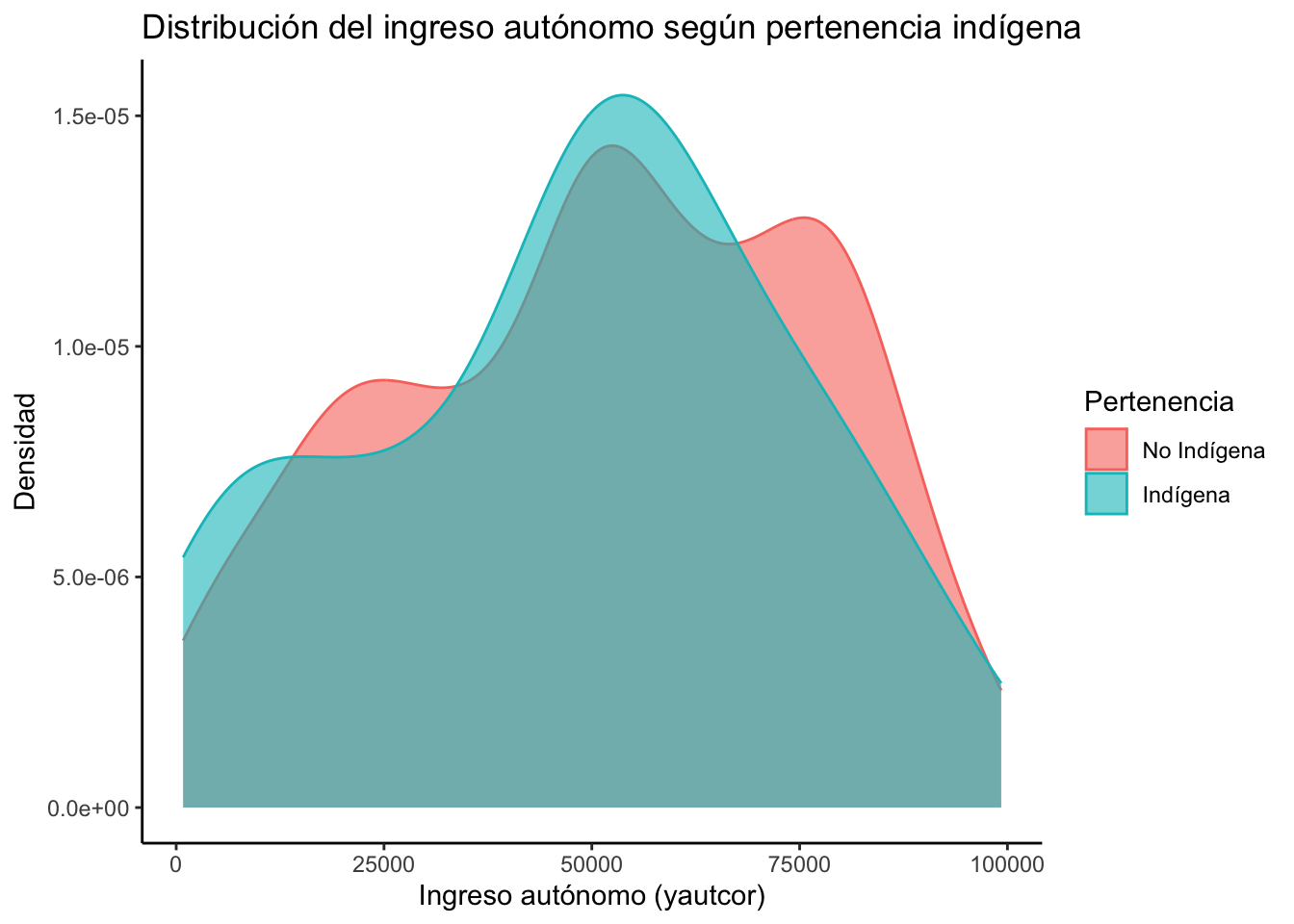
4.4 Gráfico de dispersión edad e ingreso
Este gráfico muestra la relación entre la edad de las personas y su ingreso autónomo (yautcor), con una distinción por pertenencia indígena. Se utiliza un gráfico de puntos para visualizar la dispersión de los datos individuales.
Pasos del código:
filter(yautcor < 1000001): filtra valores extremos de ingreso para mantener solo observaciones dentro de un rango razonable.ggplot(...): inicializa el gráfico asignandoyautcoral eje X yedadal eje Y.colour = as.factor(pueblos_indigenas): transforma la variablepueblos_indigenasen factor para colorear los puntos por grupo.geom_point(alpha = 0.3): agrega puntos con transparencia (alpha = 0.3) para evitar saturación visual en zonas densas.labs(...): agrega un título claro y etiquetas a los ejes.theme_minimal(): aplica un diseño limpio con fondo blanco y sin bordes.
casen |>
filter(yautcor < 1000001) |> # eliminar valores extremos
ggplot(aes(x = yautcor, y = edad, colour = as.factor(pueblos_indigenas))) +
geom_point(alpha = 0.3) +
labs(
title = "Ingreso autónomo por edad (sin extremos)",
x = "Edad",
y = "Ingreso autónomo (yautcor)",
colour = "Pueblos indígenas"
) +
theme_minimal()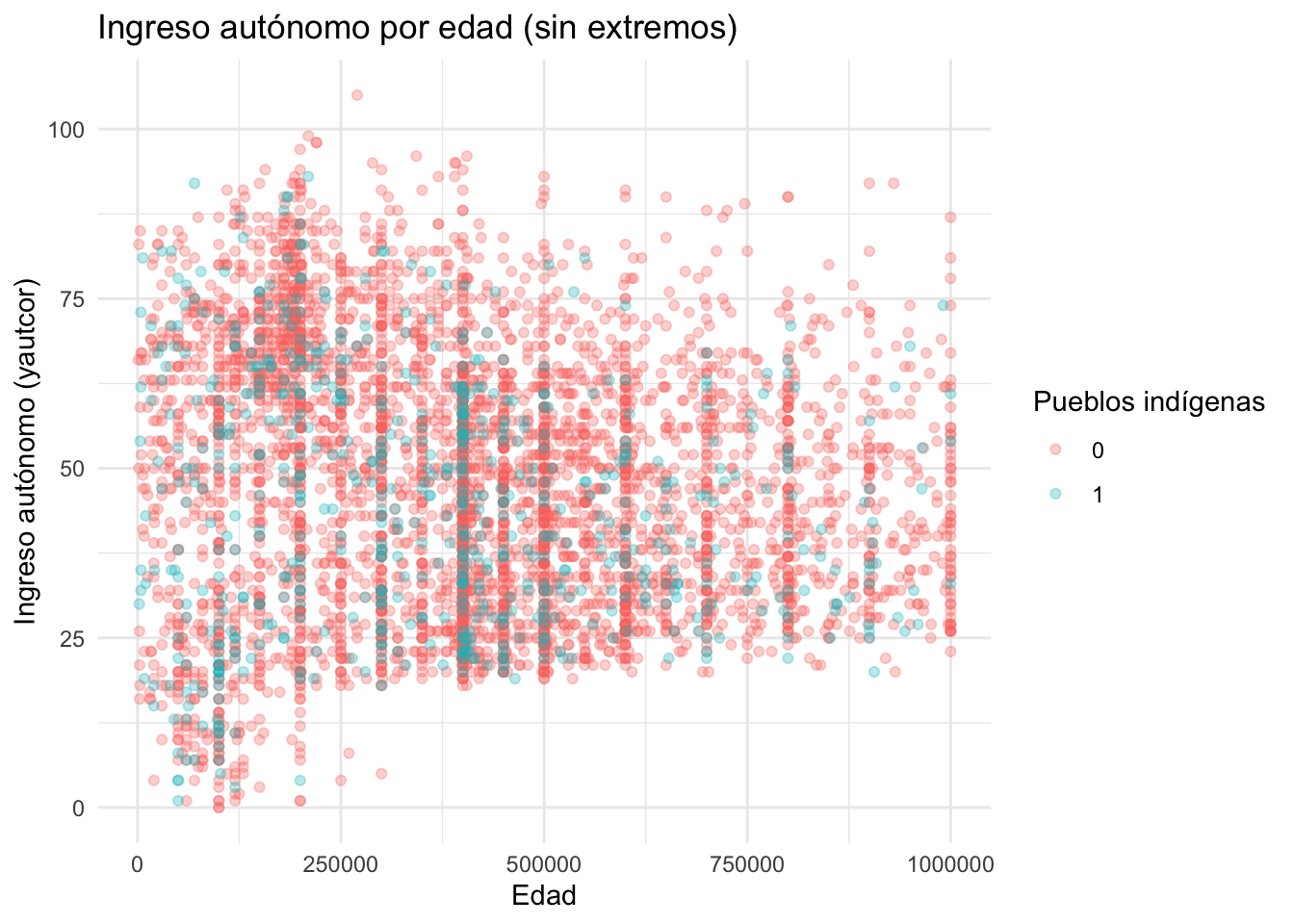
4.5 Línea de tendencia sin puntos
Este gráfico representa la tendencia general entre el ingreso autónomo y la edad, sin mostrar los puntos individuales. Es útil para detectar patrones globales cuando hay muchos datos.
Pasos del código:
filter(yautcor < 2000000): elimina outliers con ingresos extremadamente altos para evitar que afecten la tendencia.ggplot(...): define el mapeo estético conyautcoren el eje X yedaden el eje Y.geom_smooth(): agrega una línea suavizada que estima la relación entre ambas variables, utilizando por defecto un modelo de regresión local (loess).labs(...): define el título del gráfico y los nombres de los ejes.theme_minimal(): aplica un tema visual limpio.
casen |>
filter(yautcor < 2000000) |> # evitar outliers extremos
ggplot(aes(x = yautcor, y = edad)) +
geom_smooth() +
labs(
title = "Edad según ingreso autónomo (sin extremos)",
x = "Ingreso autónomo (yautcor)",
y = "Edad"
) +
theme_minimal()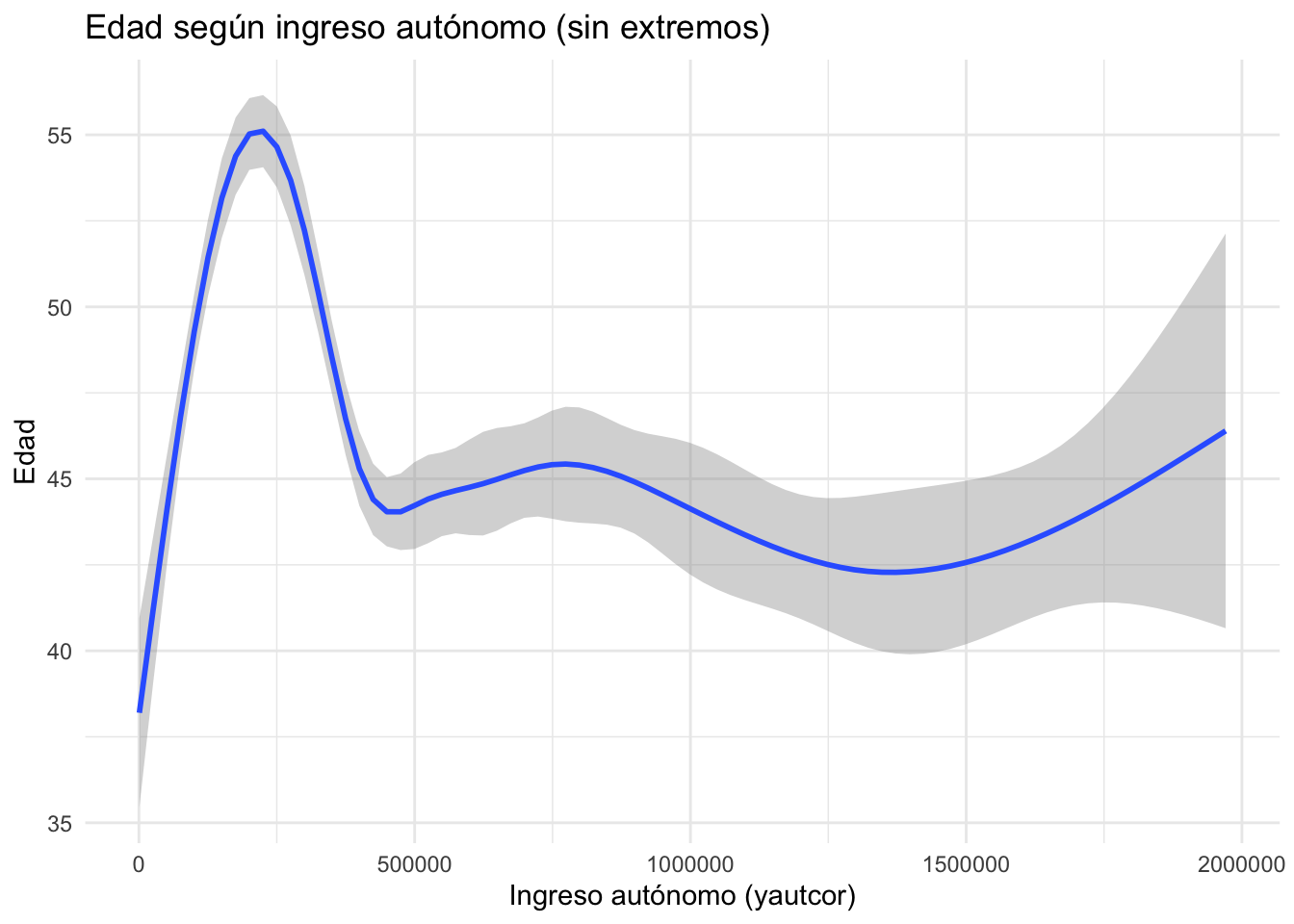
5 Gráfico de barras
5.1 Conteo de personas por condición indígena
Este gráfico muestra cuántas personas en la muestra se identifican o no con un pueblo indígena. Es útil para visualizar la distribución de esta variable categórica.
Pasos del código:
ggplot(aes(x = factor(pueblos_indigenas))): se transforma la variablepueblos_indigenasen un factor, para queggplot2la trate como una categoría en el eje X.geom_bar(): genera un gráfico de barras contando automáticamente las observaciones por categoría.labs(...): define el título del gráfico y los nombres de los ejes.scale_x_discrete(...): reemplaza las etiquetas “0” y “1” por “No Indígena” e “Indígena”.theme_minimal(): aplica un tema limpio y moderno al gráfico.
casen |>
ggplot(aes(x = factor(pueblos_indigenas))) +
geom_bar() +
labs(
title = "Distribución según pertenencia a pueblo indígena",
x = "Pertenencia",
y = "Cantidad"
) +
scale_x_discrete(labels = c("0" = "No Indígena", "1" = "Indígena")) +
theme_minimal()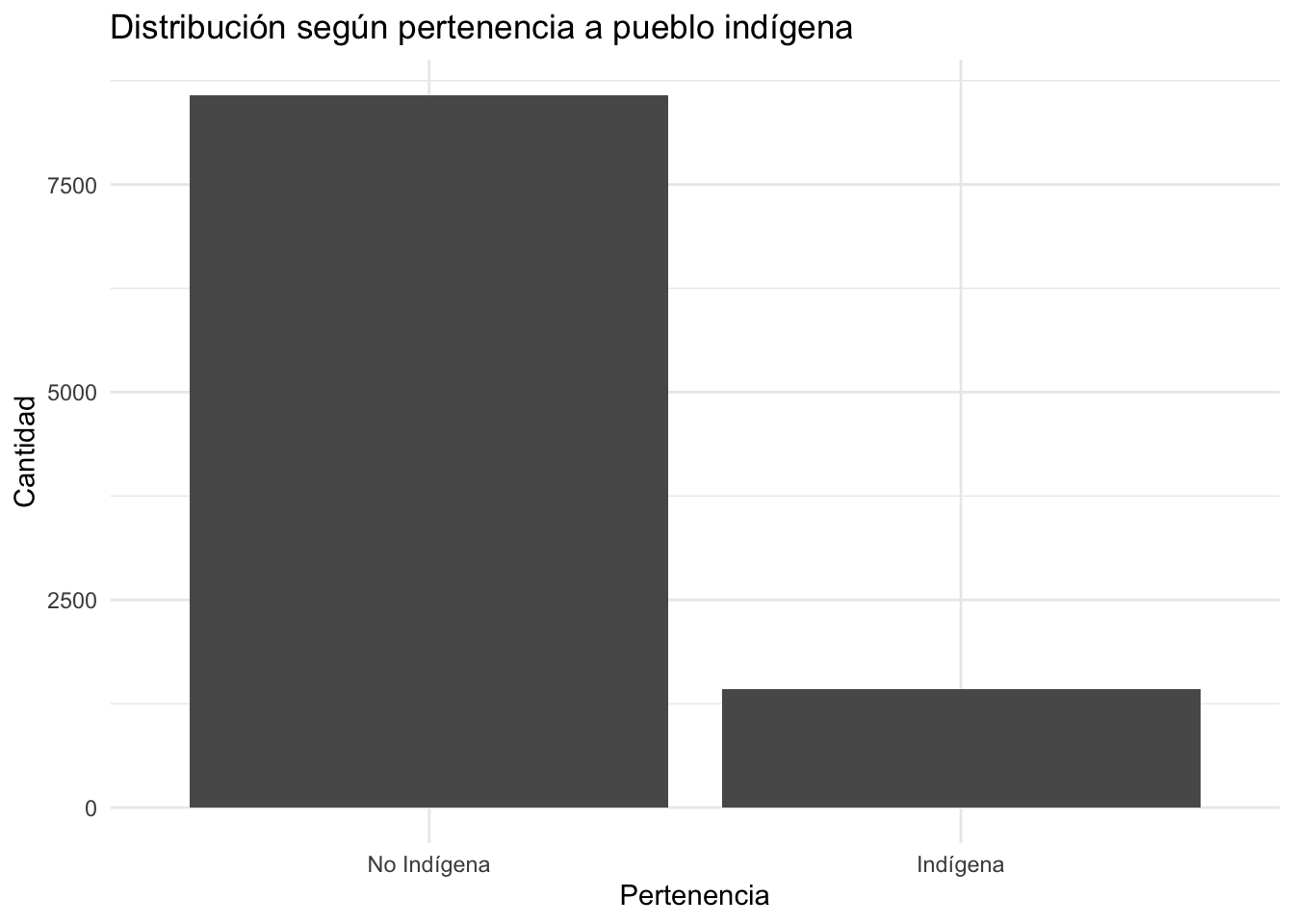
5.2 Crear variable categórica de nivel educativo
casen <- casen |>
mutate(
educ_nivel = case_when(
educ %in% 0:1 ~ "Sin educación",
educ %in% 2:4 ~ "Básica",
educ %in% 5:6 ~ "Media",
educ %in% 7:8 ~ "Técnico nivel superior",
educ %in% 9:11 ~ "Profesional",
educ == 12 ~ "Postgrado",
TRUE ~ NA_character_
)
)5.3 Agrupar y contar por nivel educativo y condición
tabla_educ <- casen |>
group_by(pueblos_indigenas, educ_nivel) |>
count()5.4 Gráfico de barras agrupadas
Este gráfico de barras compara la cantidad de personas por nivel educativo, diferenciando entre quienes se identifican como indígenas y quienes no. Al usar position = "dodge", las barras se colocan una al lado de la otra, permitiendo comparar los grupos dentro de cada nivel educativo.
Explicación paso a paso:
ggplot(tabla_educ, aes(...)): se define la base del gráfico con la tablatabla_educ, especificando:x = educ_nivel: eje X representa los niveles educativos.y = n: eje Y representa la cantidad de personas.fill = factor(pueblos_indigenas): las barras se rellenan según la pertenencia indígena.
geom_col(position = "dodge"): crea un gráfico de columnas usando los valores exactos (no conteos automáticos), y separa las barras por grupo.labs(...): agrega título y etiquetas a los ejes y leyenda.scale_fill_manual(...): personaliza los colores de cada grupo:Gris para “No Indígena”
Naranja para “Indígena”
También se cambian las etiquetas para que sean legibles.
theme_minimal(): aplica un tema claro y limpio.theme(...): rota las etiquetas del eje X 45 grados para mejorar su legibilidad
ggplot(tabla_educ, aes(x = educ_nivel, y = n, fill = factor(pueblos_indigenas))) +
geom_col(position = "dodge") +
labs(
title = "Distribución por nivel educativo y pertenencia indígena",
x = "Nivel educativo",
y = "Cantidad de personas",
fill = "Pueblos Indígenas"
) +
scale_fill_manual(values = c("0" = "#999999", "1" = "#D95F02"), labels = c("No Indígena", "Indígena")) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))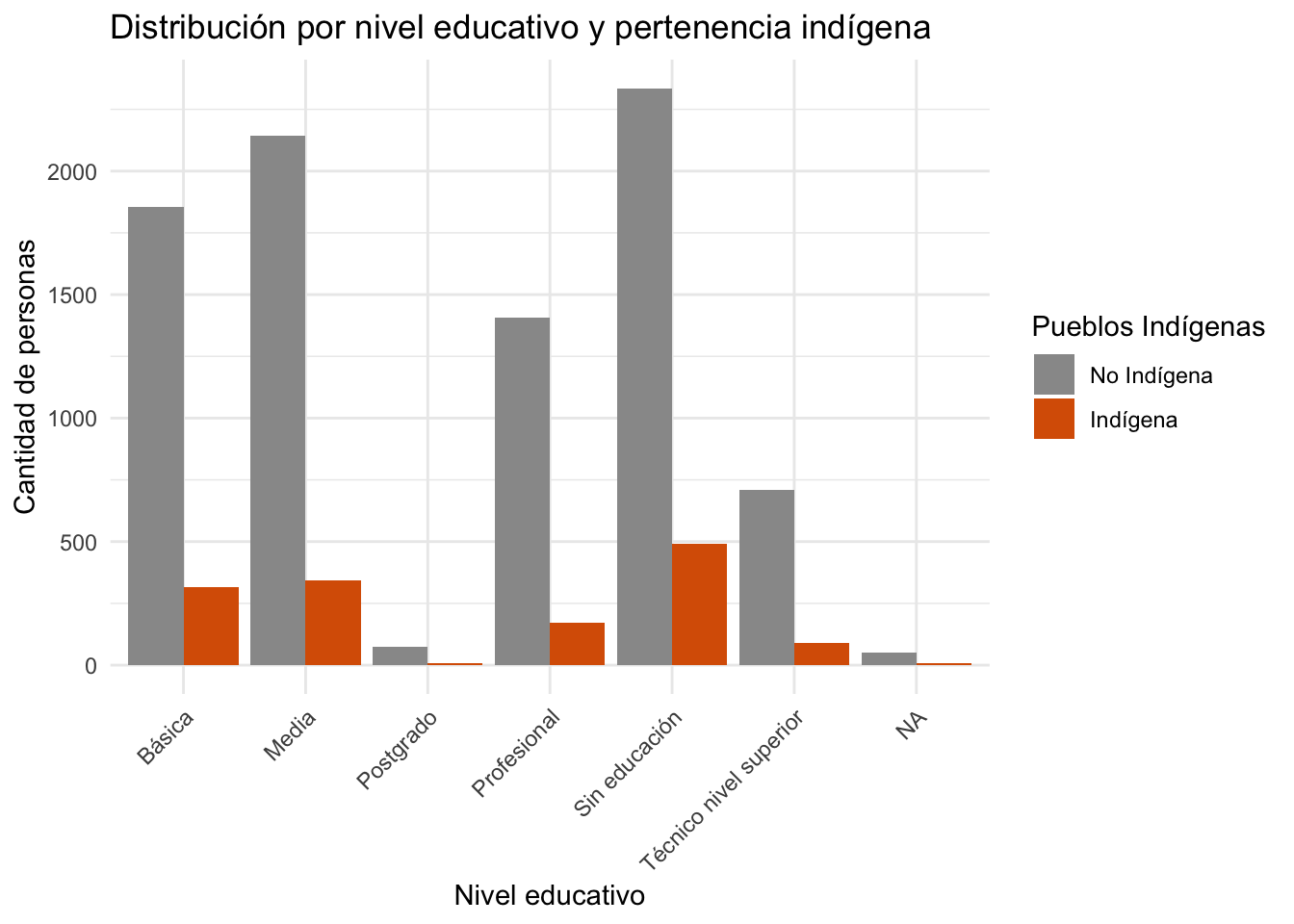
5.5 Calcular proporciones dentro de cada grupo
tabla_educ_por_grupo <- tabla_educ |>
group_by(pueblos_indigenas) |>
mutate(prop = n / sum(n)) |>
ungroup()5.6 Gráfico de barras por grupo con facetas
ggplot(tabla_educ_por_grupo, aes(x = educ_nivel, y = prop, fill = educ_nivel)) +
geom_col() +
geom_text(aes(label = scales::percent(prop, accuracy = 1)), vjust = -0.5, size = 3) +
facet_grid(~ pueblos_indigenas, labeller = as_labeller(c("0" = "No Indígena", "1" = "Indígena"))) +
scale_y_continuous(labels = scales::percent_format()) +
labs(
title = "Distribución del nivel educativo dentro de cada grupo",
x = "Nivel educativo",
y = "Proporción",
fill = "Nivel educativo"
) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))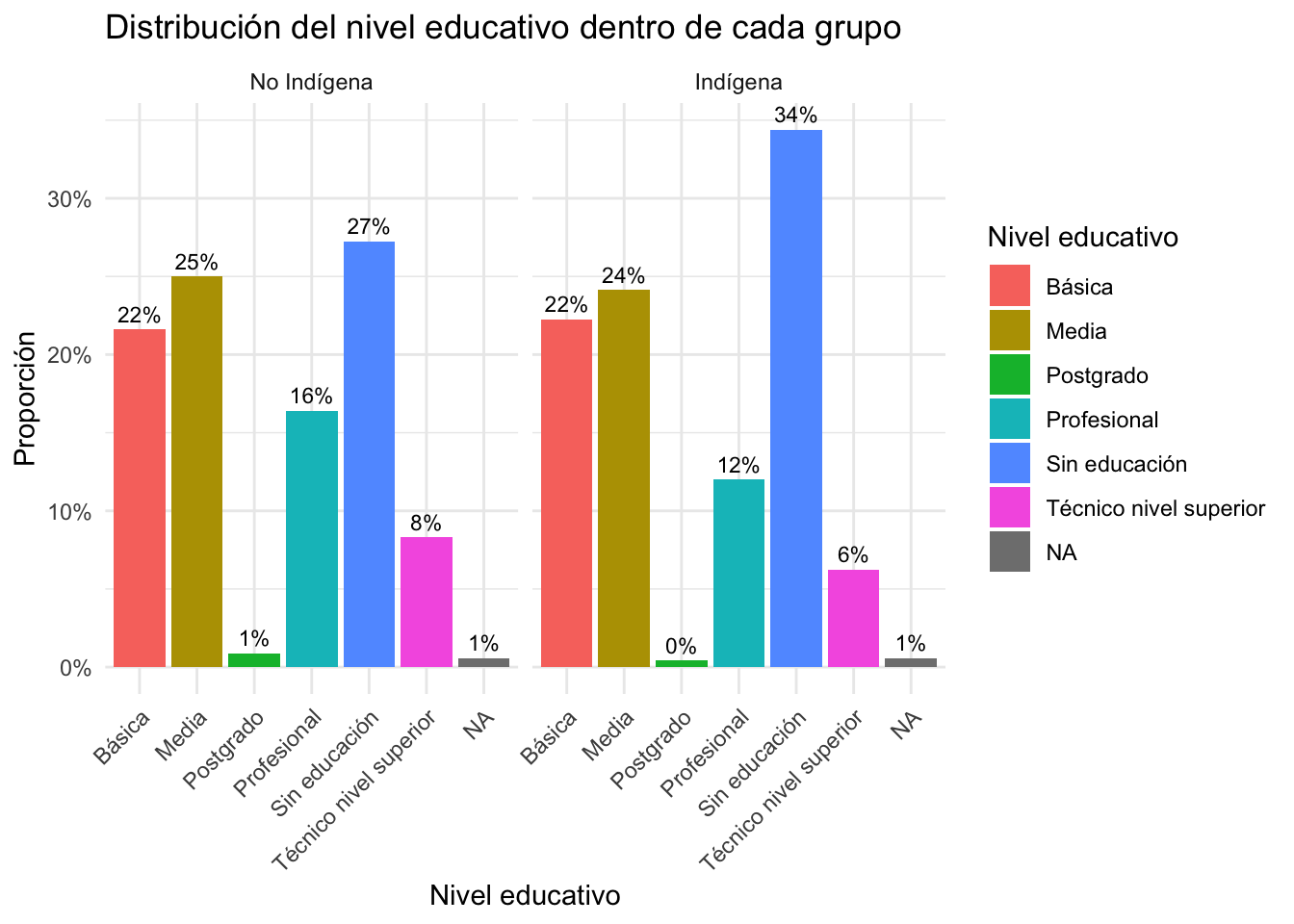
6 Gráfico de tendencia con GSS
Este bloque de código procesa la base de datos gss_cat del paquete forcats, con el fin de calcular la proporción de personas que se identifican como “Strong Democrat” en EE.UU., desagregado por raza y año.
library(forcats)
gss_party_race <- gss_cat |>
filter(!is.na(partyid), !is.na(race)) |> # 1. Elimina valores perdidos en partido y raza
group_by(year, race, partyid) |> # 2. Agrupa por año, raza y afiliación partidaria
summarise(n = n(), .groups = "drop") |> # 3. Cuenta el número de casos por combinación
group_by(year, race) |> # 4. Reagrupa por año y raza
mutate(prop = n / sum(n)) |> # 5. Calcula la proporción que representa cada partido
ungroup() # 6. Elimina agrupaciones
voto_duro <- gss_party_race |> filter(partyid == "Strong democrat")6.1 Gráfico de tendencia final
ggplot(voto_duro, aes(x = year, y = prop, color = race)) +
geom_line(size = 1.2) +
geom_point(size = 2) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))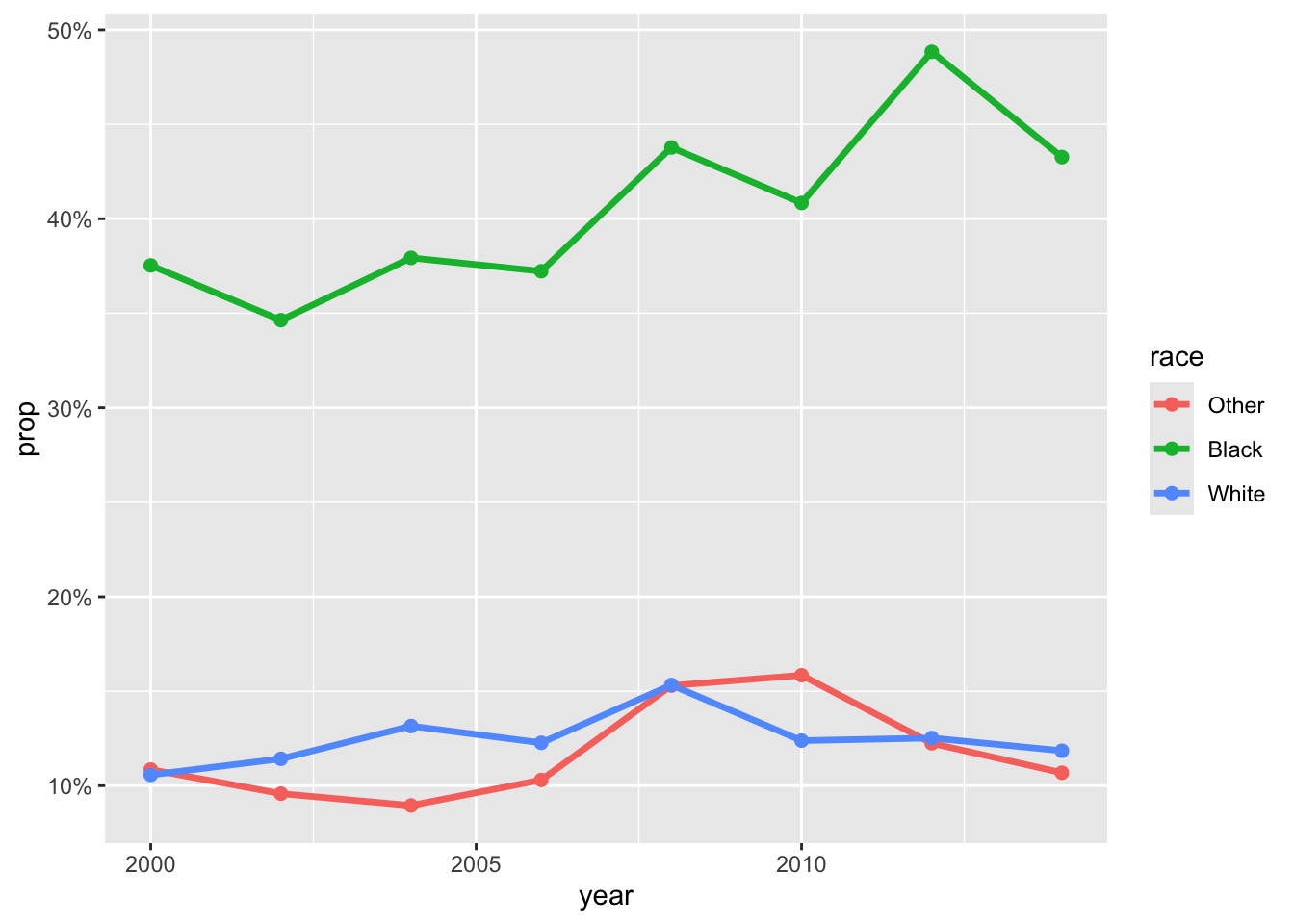
6.2 Gráfico bonito (ChatGPT 😳)
g2 <-ggplot(voto_duro, aes(x = year, y = prop, color = race)) +
geom_line(size = 1.2) +
geom_point(size = 2) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_color_brewer(palette = "Dark2") +
labs(
title = "Voto duro demócrata en EE.UU.",
subtitle = "Proporción que se identifica como 'Strong Democrat', por raza y año",
caption = "Fuente: GSS (General Social Survey)",
x = "Año",
y = "Proporción",
color = "Raza"
) +
theme_minimal(base_size = 13) +
theme(
plot.title = element_text(face = "bold", size = 16),
plot.subtitle = element_text(margin = margin(b = 10)),
plot.caption = element_text(color = "gray40", size = 9),
legend.position = "bottom",
legend.title = element_text(face = "bold"),
axis.text.x = element_text(angle = 45, hjust = 1)
); g2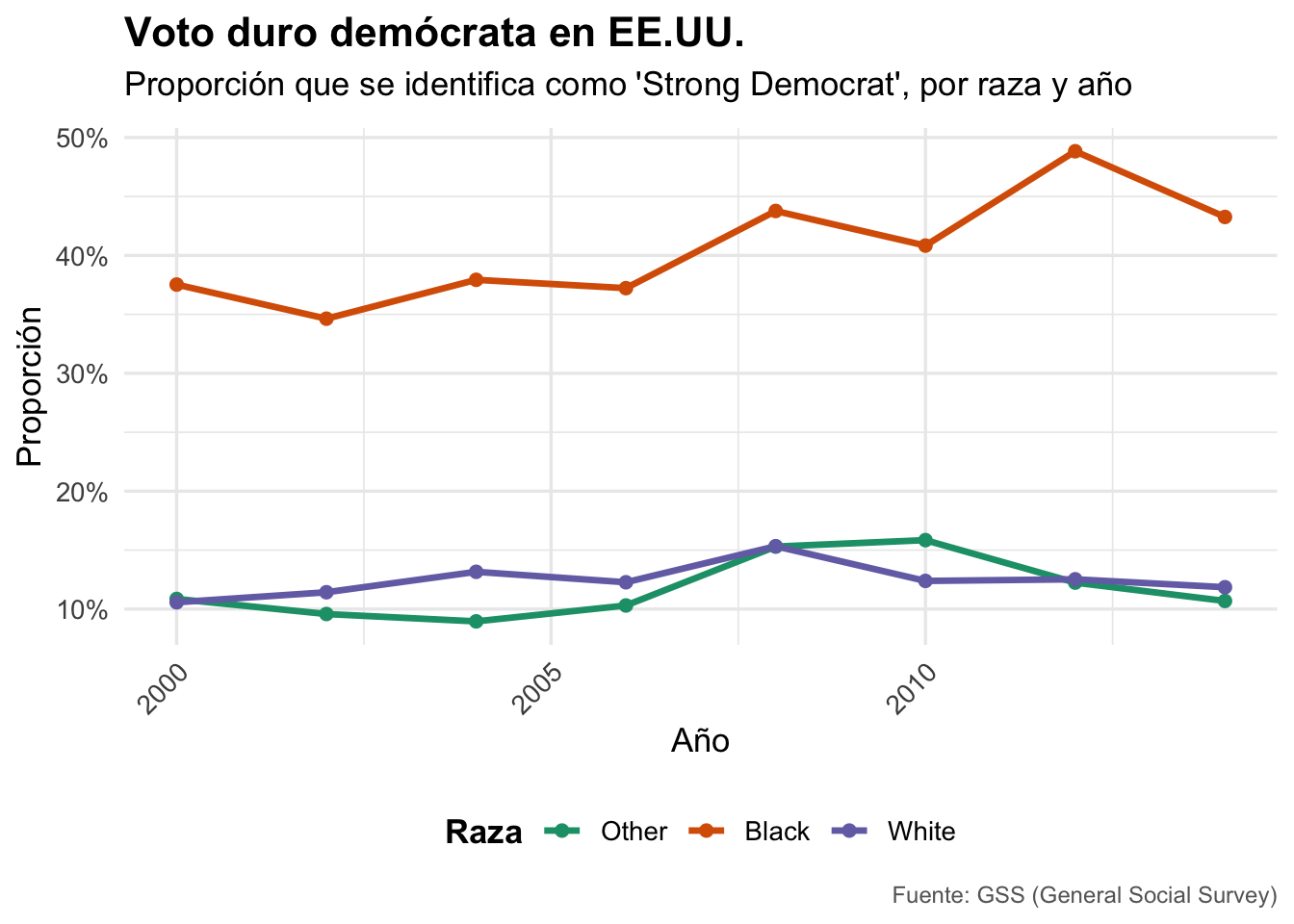
6.3 Guardar gráfico con dimensiones de PowerPoint
ggsave("images/voto_duro_race_ppt.png", plot = last_plot(), width = 29.21, height = 12.09, units = "cm", dpi = 300)