| Tuit | boric | quiere | acabar | instituciones | democráticas | libertad | individual | estado | intervencionismo | apoyo | fuerzas | armadas | orden | disciplina | respeto | educación | pública | gratuita | calidad | rol | ideología | género | proteger | familia | prioridad | nacional |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| T2 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| T3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| T4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| T5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
Análisis cuantitativo del texto II
Unsupervised learning y GeminiAI
May 22, 2025
Resultados esperados
Análisis de texto con IA 🥱
Modelamiento de tópicos (Bad Bunny songs)
¿Cómo hacer cosas con las palabras?
Pues bien; si a un cervantista se le ocurriera decir: el Quijote empieza con dos palabras monosilábicas terminadas en n: (en y un), y sigue con una de cinco letras (lugar), con dos de dos letras (de la), con una de cinco o de seis (Mancha), y luego se le ocurriera derivar conclusiones de eso, inmediatamente se pensaría que está loco. La Biblia ha sido estudiada de ese modo.Jorge Luis Borges en "La Cábala". Conferencias denominadas Siete Noches
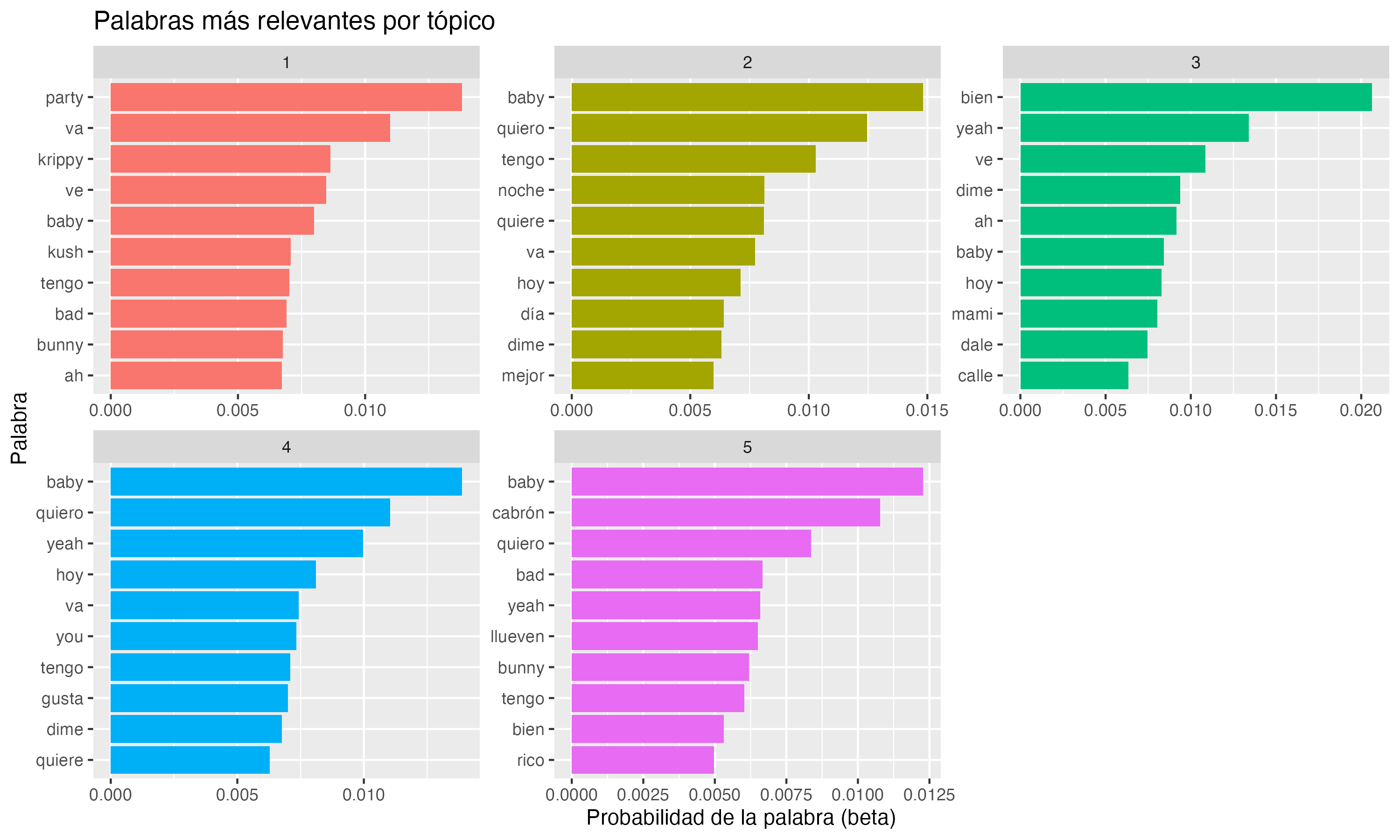
LDA en R
# Ajustar modelo LDA (3 tópicos)
lda_model <- LDA(dtm, k = 3, control = list(seed = 1234)) # Seed es para reproducibilidad
# Distribución de palabras por tópico (beta)
topics_terms <- tidy(lda_model, matrix = "beta")
# Mostrar las 5 palabras más probables por tópico
topics_terms %>%
group_by(topic) %>%
slice_max(beta, n = 5) %>%
arrange(topic, -beta) %>%
mutate(term = reorder_within(term, beta, topic)) %>%
ggplot(aes(beta, term, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~topic, scales = "free") +
scale_y_reordered() +
labs(title = "Tópicos latentes en los tweets")
¿Qué es una API?
Una API (Application Programming Interface) es una interfaz que permite que dos programas se comuniquen entre sí.
🔹 En este contexto:
Una API te permite enviar texto a un LLM desde tu código (por ejemplo en R o Python), y recibir la respuesta automáticamente.
VAMOS AL CÓDIGO!
![]()